模型杂谈
前言
在实习了两个多月的时间里,我也是深度的使用了国内外的四款较为主流的编程模型去进行对真正工程级项目的需求开发和bug修复等工作,这里也是对于各个模型等特色有了一些比较清晰的认知,突然就想写一篇文章和大家分享分享。当然以下观点只是在我自身的鸿蒙领域中各个模型的表现和实际效果,并不代表该模型的真实实力,不能全面的评价模型,每个人对于模型的需求各不相同,我们永远要遵循一个原则就是:
模型只是工具,能用最小的成本,解决你的问题,满足你的需求,才是好模型。
如果只是一味的追究模型硬实力,追求极致的知识储备和推理、编码能力,那你的成本会极速飙升同时,收益却不一定高。因为真实情况是很多人的能力远低于模型本身,你写出的提示词是一定程度上在拖模型的后腿,你的见解和决断不一定能导向最优解。
在模型能力飙升的今天,6成的问题各家旗舰模型都能解决,大多数人的需求也止步于此,再往上大多数中小型项目的2成问题,能拉开顶尖模型和普通旗舰模型的差别,再往上1成的架构问题顶尖模型可以辅助决断,最后的1成偏难怪,或是底层的问题当今的模型基本就爱莫能助了。但现实是大多数人根本摸不到模型的能力边界,所以我们完全可以根据各个模型的特性去合理分配任务,让成本被尽可能的降低。
更进一步的去说,我为什么突然想起这样一篇文章,其实是因为在现在工作中确实是遇到了能力相近的两款模型,由于其编码风格不一样导致了结果以及进度上的天壤之别。这也让我对于模型能力有了更新的认知模型能力相似的时候,很多的时候你还需要更进一步的去了解这个模型所谓的“风格”或者说是“习性”。
顶级模型
我们首先来去对比一下我最常用的两款国外毫无争议的顶级模型————Claude Opus 4.8 和 GPT 5.5。分别来自Anthropic和OpenAI。虽然Gemini 3.1 pro和3.5 flash也确实强力,但我也确实没有深度的体验过,这里就不做过多评价了。
价格方面
首先对于官方订阅来说,Claude Opus 4.8是真的贵,虽然订阅价格一致但是此前A厂下调了各个订阅档位的用量,一刀精准切在大多数程序员的大动脉上。对于国内来说,A场的长期严格封禁,以及对于中国大陆用户的监测力度之严格,导致各个中转站的号池成本也水涨船高,导致在国内使用Opus属于是一个非常昂贵的的状态了。反观open AI的GPT来说,它同等价位的订阅服务本就比A厂的量更大,而且其本身的API价格也更低,对于中国用户的封禁监管力度也相对宽松,再加上此前的1刀Team大幅度压低了中转站号池的价格,比较靠谱的一些中转站也是能做到把GPT5.5的价格压到可以和DeepSeek掰一掰手腕的,虽然你可能不信但我确实在用(便宜啊真便宜)。所以对于国内用户来讲非特殊场景一般来说还是GPT5.5是性价比首选。
(随便截取了一周的用量和价格)
(但好像最近有一些舆论风波有些陨落了)
模型能力以及风格方面
在Fable 5大人登场之前可以说GPT和Claude是分庭抗礼不分上下,两家的顶级模型从智力、推理能力、编码能力的角度都没太大差别,硬要分个高下我感觉还是Opus略胜一筹,但我感觉影响结果更大的并不是这两者的硬实力,而是这两者的编码逻辑并不一致。
大致描述一下这个业务场景,我们需要渲染一个后端接口的数据列表,客户端不直接使用后端的数据接口,而是通过一个封装好的SDK中提供的接口,SDK会完成数据的请求,清洗、格式转换、加解密等工作,最后给客户端提供一个符合业务需求的数据格式。这是一个很常见的场景对吧,任何网站、软件的开发大概率都有这样的场景,所以我就认为是一个很简单的业务需求,我就简单自己读了一下需要修改的文件的大致情况写好提示词扔给了GPT,转头开始投身到了紧张刺激的高级软件工程期末复习之中。等了半天发现还没修改完代码,我就很疑惑,因为此前已经规划完整的方案并且我也进行了初步的审核,但在落实修改这一步出现了无法结束的问题。于是我向上爬楼开始查看他做了什么卡在了哪里,发现问题出现在其测试时渲染出现了问题,无法获取数据,于是它依据一次又一次的日志,向着SDK内部进行调查,在我发现的时候它已经调查到表层接口内部三到四层的位置了。
但这时我意识到一个很奇怪的问题,就是这个SDK是个编译后的产物并不包含完整源码只有各个接口的定义以便于调用,它只能通过函数名称、参数类型、返回值类型去对一个黑盒逻辑进行一个盲猜。哇,我当场无语了,赶紧叫停了它,随后又试图引导它总结出当前困境具体是什么,结果它给出的回答是还没分析出根因,还需要进一步分析,我:???

GPT的这个逻辑很显然就是:“用户给了我一个需求,我无论如何要尽全力完成这个需求,遇到问题我要尽全力挖掘根因并试图解决。”这种设计哲学其实在Codex中的Goal mode就能看出,OpenAI想做的是能给到用户从0到1完整解决方案的模型,是想让用户将事情扔给它后就不用管了的状态,再加上codex app所具备的能力越来越多,能控制你的浏览器,能控制你的app,能处理多模态信息,它就是想接管用户方方面面的工作去尽力完成。但是这在一个有完善架构设计,完善接口封装,责任分工的软件团队中并不一定是件好事。它容易分不清自身的责任边界,其他人的接口也可能存在错误不能全盘相信,该寻求帮助的时候要向用户提出需求才更能适应这样的业务场景。一旦这个根因并不在他的职责范围之内就很容易导致一系列错误的“原因探查”(无用功)。
随后我回滚了代码,再次将需求发送给了Opus 4.8,让他重新分析设计方案。Opus很快就设计好了方案,我查看了方案文档设计的和GPT基本一模一样,然后编写代码,实机测试,发现了相同的问题。但他思路很清晰,打印了两轮日志,一轮检查渲染层,一轮检查数据接口层,发现数据接口请求成功但是数据为空,就当机立断很果断的下了判断是接口内部错误,是SDK内部处理数据的问题。后来我联系同事进行排查证实了Opus的想法,最终我使用Opus的修改方案实现了这个需求。
我又回去审视了一下GPT的操作记录文档和日志,发现其实它最初判断到了是接口内部问题,但是它认为它需要去找到根因并告知用户,甚至它探索编译后产物的链路与真实问题的链路也很接近,只是因为他是黑盒,没法锁定真正的根因导致他开始了更广泛更深度的检查,在客户端的数据接口层写了很多参数调整的冗余逻辑。哎,只能说是这种“特性”并不适用于这个场景但也称不上是缺点,只能说是这种经验只有针对于自身实际的开发场景才是有效的,如果脱离了实际的开发场景这种经验基本毫无意义,不只是因为不同开发场景,更是因为不同技术栈之间的差异巨大对于模型在训练阶段所包含的知识储备也存在巨大差异,就像是我的鸿蒙开发领域,相对来说是在软件开发中训练语料最少的了,现在的开发模式基本都是依赖现有代码以及一些skills去进行开发独立开发的成功率和代码可靠性都是很低的。这种场景下就可能会有模型对于鸿蒙SDK特性掌握程度不够导致无法作出准确判断的可能,导致了大量冗余操作也是可能的。或许同样的场景不是鸿蒙而是web或者是安卓,就不会有这种问题也说不定。
在后续的实践中我在提示词和规则文档中都额外新增了一条规则就是要明确权责边界,严禁过度深入调查依赖包内部结构、逻辑,并且我自己也长了记性,在每次它分析完后我都会去阅读它第一条输出的判断,这个判断一般来讲都是对于问题关键问题的分析或是最核心的修改方案结论,看一下这行的内容就能大致的掌握它的方案,如果发现存在我不熟悉的接口或是认为它的方案有些麻烦了就会及时ctrl c打断并询问相关接口组件的功能让他讲解随后我根据具体代码去大致阅读来为他指明方向,这样能大幅减少其判断错误的可能性。
国内旗舰模型
对于国内旗舰模型大多都是开源模型,当前我的主力模型是DeepSeek V4 pro和Kimi K2.6。这两个模型各有各的特点,将两者联合使用可以达到1+1>2的效果。
DeepSeek V4 pro


对于大D老师,我只能说梁圣的恩情还不完。大D老师不会亏的,因为每个交易日早上梁圣会去大A取钱的。
dsV4pro的最大优势就是在于其是最低廉成本的1M上下文,1M上下文和256K上下文是有着本质区别的,尤其是对于需要在成熟的中大型项目上去进行Vibe Coding,模型的上下文长度是至关重要的。一方面是需要模型读的内容量大,另一方面则是越复杂的工程你需要给他设置的约束越多,以及需要与它进行讨论设计的方案次数也越多。一旦出现上下文的压缩我们的上下文信息精度势必会出现削减,我们势必会遗漏一些细节。这有时就是这次修改的成败关键。同时哪怕在压缩之后我们需要让他完整阅读把握的关键代码依旧需要其去重新进行阅读分析,这就会导致上下文占用长期居高不下,工作越是进行越是需要频繁的压缩。
而相对的,1M的上下文支持我们将绝大多数项目的完整上下文毫无遗漏的全都塞到上下文窗口中,能一次行去完成一个单元工作的编码。
但我们还需要进一步的处理大模型注意力的问题,长上下文注意力会随着上下文的增加而削弱,模型可能会忽略一些关键信息,所以我们就需要在提示词中手动的点出关键的点。这一点对于DS来说尤其重要,在我Coding的过程中始终要求的都是要让模型在操作代码的同时去git commit同时将其对应的哈希值和操作概要编写到文档中以便于回滚以及日报的编写的,但是DS是我目前发现唯一一个旗舰模型还会出现修改完代码没有编写文档的模型,同时也是唯一一个需要我反复提醒这件事的模型。
虽然说大D老师的能力固然是不错的,是能处理很多开发场景的,但是这个注意力上还有多模态的缺失确实是限制了其上限。
Kimi K2.6
在我编写这篇文章的时候 kimi-k2.7-code及其高速版发布了,但是我还没试用所以就先暂时不做评价。K2.5出的时候确实是给了我不小的惊喜,同时它作为国内开源的原生多模态模型,其编程能力也不容小觑,其前端实力可以说是直逼Gemini 3.1pro的水平了。谷歌也真是废物,隔了一年了更新频率和大D老师一样了还只端出来个Gemini 3.5 Flash,哎没招了。
但相对来讲,K2.6的原生多模态在加上Kimi Code的优秀Agent素质,确实是很能打的选择,核心问题只是在于,其上下文长度和价格,都无法被称为优势。首先上下文方面,Kimi家的三个旗舰模型都是256K,并不支持1M,基本上开发一个需求点后就得新开对话,大一点或多轮次修改时还是得看着上下文窗口的条的,相对来讲用起来没那么爽,同时其价格并不占优。在我拥有0.1倍率乃至是0.05限时特价倍率的GPT5.5时,Kimi的价格可以说得上是贵了。所以我现在基本上是中转站挂了还需要处理多模态任务时才会去用。总而言之,Kimi到26年6月还是国内最夯的多模态模型这一块还是没毛病的。
GLM5.2
GLM5.2,被称为表现仅在神话模型之下的纯文本模型,这一点说真的我觉得大概率还是编的但是说它和GPT5.5不分高下我应该是信的。我靠Start Plan和50块钱的API简单体验了一下,确实不错,但也没感到那么惊艳。可能是我用的太少了还没挖到它能力的边界,但这是我的问题吗???不是!!!
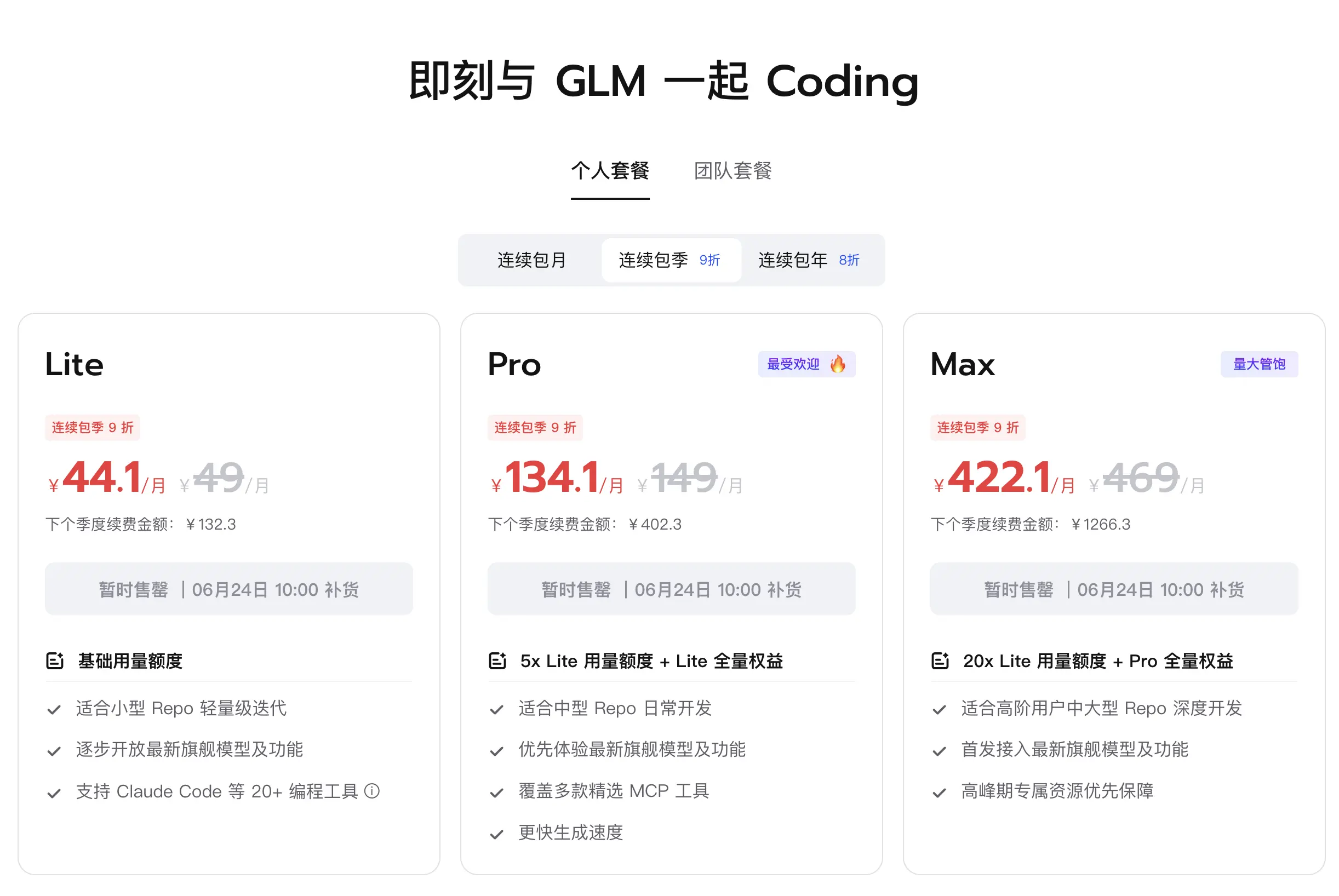

到底是谁在抢到GLM的Plan啊!!!抢了多少天了此次瞬间就是购买人数过多然后就售罄了???!!!智谱你恶事做尽啊!!!
当然还有一段血与泪的教训,绝对不要在没有报销的情况下去用API啊,会变得不幸的,太贵了。





首页星空与文章阅读可读性再次升级!

今日更新:
- 首页瀑布流卡片的信息区改为直接透出全屏动态星空,保留六组深色玻璃配色差异,让每张卡片更有层次,同时不新增 Canvas、粒子或动画预算。
- 背景与顶部封面星空统一调整为更明亮、更大一些的冷蓝白星光,流星和尾迹同步增强可见度,原有 30fps、粒子数量与性能边界保持不变。
- 移除文章卡片标题、摘要后方的大范围暗色雾层和标签暗色底,让星光自然透入;标题、日期、标签和摘要继续保留轻量投影以确保清晰。
- 修复 Butterfly 自带 `{% note flat %}` 提示区块的文字颜色,浅色提示背景内统一使用近黑色文字,信息、警告和危险提示均更易阅读。
愿星光更明亮,文字更清晰,每一次阅读都能保持舒适。✨
本次更新:
首页与文章阅读体验再次升级!
本次更新:
- 首页瀑布流悬浮光晕改为更柔和的连续水波,半径缩小约一半,并统一为青色、绿色与冷白色相间。
- 文章主内容区切换为透亮的黑深蓝夜空磨砂背景,淡青色星点和环境光可以透出背景图。
- 正文、标题、链接与弱文本同步调整对比度,阅读模式、代码块、引用块和图片样式保持兼容。
愿每一次浏览,都能在清晰与氛围之间找到刚刚好的平衡。✨
本次更新:
Markdown 工作台完成深度升级!
本次更新:
- 编辑器升级为接近 VS Code 的本地优先工作台,支持 Markdown 高亮、行号、搜索替换、命令面板、自动保存、导入导出与安全预览。
- 修复编辑区背景缺失、桌面分栏错位、预览越界和全屏底部黑区;全屏布局现在会完整填充视口。
- 桌面进入全屏后默认左右分屏,并在顶部提供更醒目的“源码 / 分屏 / 预览”切换按钮;移动端继续使用单面板模式。
- 预览始终经过安全净化,脚本、事件属性和危险链接不会执行;草稿只保存在当前浏览器,不上传服务器。
愿每一次敲下键盘,都能更顺畅地把想法写成作品。✨
本次更新:
昨日重现,重新浮现!
本次更新:
- “昨日重现”照片墙完成重构,照片会随机播放,向上或向下滚动都能在视野中梦幻浮现;离开视野后隐入,再次经过时重新出现。
- 图片改为真正的近视口懒加载,只有接近视野才会开始请求,并通过统一队列限制并发,尽量减少小带宽服务器的压力。
- 重建图片清单与布局系统,提前根据图片尺寸保留位置,减少滚动时的跳动;“重新随机排列”按钮也不再把浏览器 HTTP 缓存误称为可清除的图片缓存。
- 新增可配置的 WebP 压缩工具,可按质量、最长边和压缩方式优化图库;本次仅完成 dry-run 检查,未直接修改照片原文件。
愿每一段旧时光,都能在下一次滚动时温柔地浮现出来。✨
本次更新:
公告历史时间轴已上线!
本次更新:
- 公告栏已支持纵向时间轴,可继续查看每一版历史公告;
- 每一版公告都会标记发布时间,历史内容可以通过 Git 记录追溯恢复;
- 新公告统一维护在 source/_data/announcements.yml,后续新增只需在文件顶部添加一条记录。
感谢你的测试与反馈,欢迎继续探索这个会不断成长的小站!✨
近期优化已完成:
欢迎来到神秘的小破站!
近期优化已完成:
- 首页瀑布流升级为按需响应式 3/2/1 列布局,移除高频轮询与冗余调试;
- 清理失效资源请求,修正本地图片兜底与历史路径;
- 文章图片保留原生懒加载,仅近视口显示轻量占位效果;
- 目录跳转会在图片晚到时自动校正标题位置,桌面与移动端均已适配。
愿你在这里阅读顺畅、探索愉快,收获每一份灵感!✨
近期优化已完成:
欢迎来到这里!
近期优化已完成:
- 首页瀑布流升级为按需响应式 3/2/1 列布局,移除高频轮询与冗余调试;
- 清理失效资源请求,修正本地图片兜底与历史路径;
- 文章图片保留原生懒加载,仅近视口显示轻量占位效果;
- 目录跳转会在图片晚到时自动校正标题位置,桌面与移动端均已适配。
愿你在这里阅读顺畅、探索愉快,收获每一份灵感!✨
欢迎来到这里!
欢迎来到这里!
本站近期完成首页瀑布流性能优化:移除高频轮询和冗余调试逻辑,改为响应式 3/2/1 列布局,并按需重新排版。
希望能带来更稳定、轻快的浏览体验!
welcome!
welcome!
近期进行了不少的优化,也不知道大家感受出来没,加载速度啊、目录跳转稳定性啊巴拉巴拉的。
总之祝大家2026新春快乐!!!
(也是开始上班了呢]
welcome!
welcome!
近期进行了不少的优化,也不知道大家感受出来没,加载速度啊、目录跳转稳定性啊巴拉巴拉的。
总之祝大家2026新春快乐!!!
welcome!
welcome!
welcome!
welcome!
热烈庆祝鸿蒙五终端数量突破两千万!!!
热烈庆祝鸿蒙五终端数量突破两千万!!!

鸿蒙生态,星河璀璨!
鸿蒙生态,星河璀璨!
本站由于服务器带宽有限,设置了文章图片懒加载,滚动停止后才会开始加载图片,遇到加载中的图片请静止等待
本站由于服务器带宽有限,设置了文章图片懒加载,滚动停止后才会开始加载图片,遇到加载中的图片请静止等待
笑死还说假期填坑呢,倒是给自己新开了个无底巨坑
笑死还说假期填坑呢,倒是给自己新开了个无底巨坑
最近也是给自己挖了挺多坑还没填上的等暑假慢慢填吧,争取暑假把自己想写的都写上。
最近也是给自己挖了挺多坑还没填上的等暑假慢慢填吧,争取暑假把自己想写的都写上。
主页大翻新啦!!!快来看快开看啊!!!
主页大翻新啦!!!快来看快开看啊!!!
ICP备案完成!xbxyftx.top正式恢复运营!!!
ICP备案完成!xbxyftx.top正式恢复运营!!!
25年的计划开始执行了吗?
25年的计划开始执行了吗?
This is my Blog
This is my Blog